

Aligning Discrete Generative Models to Any Reward, at Any Length
A 20-minute breakdown of our newest work, “A2D2: Fine-Tuning Any-Length Discrete Diffusion for Adaptive Decoding”

A little over a year ago, we published PepTune, a framework for multi-objective optimization of discrete diffusion models. PepTune steers generation purely at inference time. In other words, it never changes the underlying model; it just biases each unmasking step toward sequences with high rewards.
It worked really well, but left an open question: if the model keeps proposing sequences with suboptimal rewards, can we change the model itself instead of paying the cost of guidance at every generation round?
This question is what pulled me from inference-time guidance toward reward alignment, where we fine-tune the generative model so that high-reward sequences become the ones it generates unconditionally.
It was the motivation behind the TR2-D2 paper, which made reward fine-tuning of fixed-length discrete diffusion principled and stable, and has now led to our newest work, “A2D2: Fine-Tuning Any-Length Discrete Diffusion for Adaptive Decoding,” which unlocks reward alignment for any-length sequence generation that decides not just what tokens to generate, but how many.
The standard generation process of discrete diffusion is unintuitive. For instance, we (humans) typically don’t start writing knowing the exact number of words that should go between every pair of words. We don’t block out a span of “masks” with the thought: “Oh, I will fill that exact number of blank tokens later.”
Instead, we write sequentially, and gradually fill in and edit missing sentences and words in between. That is what got me interested in any-length generation, which is the paradigm we focus on in this work.
Before we begin, I wanted to thank everyone for 500 subscribers! I started this Substack almost two years ago as a way to learn through writing and force myself to fill in each and every gap in my knowledge, but I never could have imagined how it would transform my life and research trajectory. I’m beyond grateful to have a small community on here to share new research with.
Going forward, I plan to post more consistently beyond just my own research and am open to suggestions! If you have any topics that you would like covered or want to write a guest post, feel free to email me at sophtang@seas.upenn.edu.
This article is a conceptual tour of reward alignment for discrete diffusion. We’ll build up from why reward alignment matters, formulate alignment as an entropy-regularized reward optimization problem, present tractable and stable off-policy reward alignment with TR2-D2, and finally provide an overview of our newest framework, A2D2, which unlocks reward alignment for any-length generation. Let’s dive in!
Why reward alignment?
A pretrained generative model learns to sample from a data distribution. A protein diffusion model trained on UniProt learns to produce sequences that look like natural proteins; a molecular model trained on ZINC learns to produce molecules that look like the collection of commercially available chemical compounds. This is exactly what pretraining should do, but it is rarely what we actually want.
What we want is a sequence that is good by some external, often non-differentiable, measurement: a peptide that binds a target with high affinity, a molecule that is synthesizable and drug-like, an mRNA that is stable and can be translated efficiently.
However, the high-likelihood modes of the data distribution are not aligned with the regions of high reward. Most natural proteins don’t bind your target, and most chemical compounds aren’t great drugs.
There are two broad ways to close this gap.
The first is inference-time scaling or guidance, which is what PepTune and mRNAutilus do. You leave the model frozen and, at sampling time, steer each step toward high-reward regions using the gradient of the reward or value function. For non-differentiable rewards or trajectories on discrete state spaces, this is a bit more complex (which is the premise of our previous works). But overall, inference-time steering is plug-and-play and requires no retraining, but it pays a price every time you sample and can only steer as far as the frozen model’s distribution supports.
The second is reward alignment (aka reward fine-tuning): you actually update the model’s parameters so that its own sampling distribution shifts toward high reward. This is precisely the idea behind Reinforcement Learning from Human Feedback (RLHF) for language models, which turned raw next-token predictors into helpful and accurate reasoners. We pay the optimization cost once, and every subsequent sample is cheaper and better.
The natural question is how to do reward alignment without destroying everything the model learned in pretraining. We don’t want a model that only outputs the single highest-reward sequence (that’s reward hacking, and it collapses diversity). We want to tilt the distribution toward reward while staying close to the realistic, valid manifold the pretrained model represents.
Stochastic processes in discrete state spaces
If you’ve seen diffusion models for images, you’ve seen how stochastic differential equations (SDEs) enable generation: a particle drifts and diffuses through a continuous space, and generation is the reverse of a noising process, which is steered by the score function (gradient of the log-likelihood).
But sequences (text, amino acids, nucleotides, SMILES characters) don’t live in a continuous space, but in a categorical or discrete state space.
The right object for a stochastic process over a discrete state space is a continuous-time Markov chain (CTMC). Instead of drifting smoothly, the process sits in a state and, at random times, jumps to a different state. How often it jumps, and where to, is governed by a rate matrix Q (or generator), which is the discrete analogue of the drift in an SDE:
whose value Q(x, y) describes the transition rate from a state x to another state y.
Discrete diffusion models are a practical instance of this theory. The process starts from a sequence sampled from a prior distribution over the vocabulary and, over a time horizon from 0 to 1, each token along the sequence makes discrete jumps toward the clean sequence distribution.
Training is just denoising: from an intermediate sequence along the time horizon, predict transition rates (often parameterized with the categorical distribution over the vocabulary) that generate the clean sequence.
The key idea here is that generation is a path through a discrete state space. Each unmasking step is a jump. A whole trajectory, from all-masked to fully-clean, is one realized path, and the model defines a probability measure over paths. This “measure over trajectories” view is exactly what lets us define a model that generates a tilted distribution while remaining close to the original distribution.
Reward alignment as entropy-regularized optimization
The goal of reward alignment is to find the rates that control the CTMC so that the distribution it lands on at the end of the process is tilted toward high reward, while staying close to the pretrained process.
To make the tilting mechanism precise, suppose we have a reward function and the pretrained data distribution. The distribution we actually want to sample from is the reward-tilted distribution, defined as:
Intuitively, this equation is saying start from the data distribution, then exponentially up-weight sequences in proportion to their reward. The scalar α controls how aggressive the tilt is: a small α lets the distribution diverge more from the data to optimize the reward, and a large α ensures closeness to the data, and the constant Z in the denominator is just the normalization so that the distribution integrates to 1.
Since a generative model produces continuous time trajectories that terminate at the target distribution, we lift the tilt from the endpoint distribution up to the whole path measure lets us define the optimal reward-tilted path measure:
where the reference measure is the path measure of the pretrained process. Its endpoint marginal is exactly the reward-tilted distribution above.
The catch is that we can write down this target, but we cannot actually sample from it — it’s intractable, and we have no target samples to evaluate the loss with. We only have a reward function that we can evaluate on a given sequence.
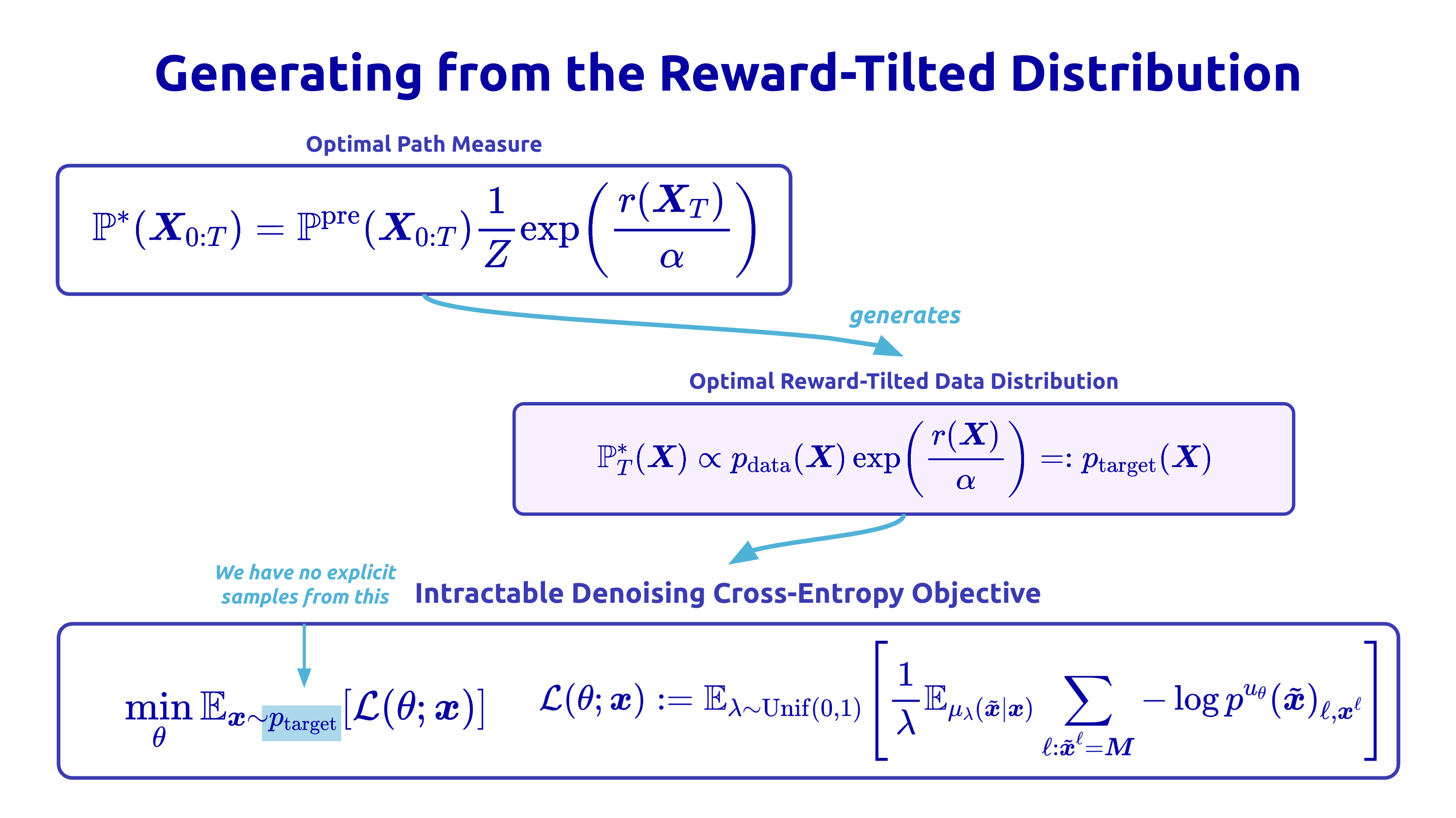
This means we can’t just do supervised learning on examples from the target; we have to somehow move the model distribution toward it indirectly, using only a reward we can evaluate.
Finding the fine-tuned rates that reproduce the optimal tilted measure turns out to be equivalent to the entropy-regularized reward optimization problem:
The first term is the expectation of the final reward over all trajectories, and the second regularization (KL divergence) term is the anchor that keeps the fine-tuned process close to the pretrained one (so we don’t reward-hack our way off the valid manifold).
And it has a really nice property: it’s maximized exactly when the fine-tuned process equals the optimal tilted measure. This isn’t just a heuristic regularizer added to the reward; it’s the objective that uniquely gives us the intractable reward-tilt of the pretrained distribution.
Off-policy reinforcement learning
Knowing the objective is one thing; optimizing it stably is another. The most direct approach is on-policy reinforcement learning (RL), where we are minimizing the KL divergence from the model’s distribution to the target. In this setting, the expectation is taken over the model’s current distribution, which shifts after every gradient step.
On-policy RL on discrete diffusion models is known to be unstable and has a specific failure mode: the model samples its own trajectories, some of them low quality, and then reinforces those low quality trajectories, which can often lead to collapse in those regions.
The fix is to go off-policy. Instead of the moving target (the model’s own shifting distribution), we can take the expectation over a fixed reference measure. Concretely, swap the KL around to the cross-entropy form:
This results in a two-stage procedure:
First, we sample trajectories from any convenient reference measure (for instance, a detached, frozen copy of the current model), not from the live, moving model distribution. This decouples generating data from updating the model, which is what makes training stable. In practice, we generate a batch of sequences, store them in a replay buffer, and train on them.
Then, we correct for the mismatch with an importance weight, defined as the Radon–Nikodym derivative (RND) between the target and reference path measures. This reweighting is what guarantees that, in the infinite-sample limit, training on samples from the reference measure provably converges to the true reward-tilted target.
The RND requires some computation. For a CTMC, it has a tractable closed form: it accumulates, along each trajectory, the log-ratio of pretrained-to-finetuned rates at every jump, plus the terminal reward. We bundle this into a single per-trajectory importance weight, which is then used to reweight a simple cross-entropy loss.
The result is a weighted denoising objective: the same cross-entropy loss the model was pretrained with, just with each trajectory’s contribution scaled by a reward factor (with the likelihood ratio) to bend the distribution toward reward.

The key takeaway here is that off-policy RL with RND reweighting is the move that makes reward fine-tuning of discrete diffusion both stable and provably convergent to the reward-tilted target, without ever needing samples from that target.
Aligning fixed-length discrete diffusion with TR2-D2
TR2-D2 (Tree Search Guided Trajectory-Aware Fine-Tuning for Discrete Diffusion) is where we first put all of this together, for fixed-length discrete diffusion. It combines the off-policy objective above with one more idea: don’t just generate independent trajectories from the current model; use a structured search algorithm to discover good trajectories.
If you fill the replay buffer with whatever the current model rolls out when it has not yet converged to the reward-tilted distribution, you waste most of your training budget on suboptimal sequences.
Instead, TR2-D2 uses Monte Carlo Tree Search (MCTS) to build the buffer, preferentially collecting high-reward trajectories. Then it fine-tunes the model on that buffer under the SOC objective, using the RND-weighted cross-entropy loss. These two components reinforce each other:
Tree search supplies a buffer concentrated on high-quality paths, so the model learns from the trajectories that are representative of the target distribution. This also enables a principled way to optimize multiple rewards without collapsing into a single scalar, by propagating vectorized rewards and maintaining the Pareto-optimal set of sequences that account for the tradeoffs between objectives.
The off-policy weighted loss ensures that learning from this non-uniformly-sampled buffer still converges to the correct reward-tilted distribution, rather than overfitting to the biased search likelihoods.
This framework unlocks principled, stable reward alignment for both single- and multi-objective sequence generation, all without the trajectory-reinforcement pathology of on-policy methods.
One framework, diverse modalities and rewards
What makes the TR2-D2 framework so powerful is its generalizability. The reward is a black box, and optimizing it does not require gradients. This means we can freely swap the vocabulary, swap the reward, and the same SOC theory applies.
We have demonstrated this across modalities, including DNA and peptides in the original paper, in addition to full-length mRNA optimization and drug-like small molecule design in our lab’s follow-up work.
This has also worked with diverse definitions of the reward. The reward doesn’t have to be a simple scalar predictor; it can encode rich, structured design intent. A nice example is our recent ICML spotlight paper, “TD3B: Transition-Directed Discrete Diffusion for Allosteric Binder Generation,” which designs protein binders with a specified functional direction (agonist vs. antagonist) rather than just high binding affinity.
It does this with a gated directional reward: a direction oracle scores whether a candidate pushes the target toward the desired functional state, and a soft binding-affinity gate multiplicatively gates that directional signal, so a sequence is only rewarded for directionality once it actually binds.
This decouples what the binder does from how tightly it binds, letting you steer toward agonism or antagonism of targets like GPCRs. Whether it is gated rewards, multi-objective Pareto rewards, or directional rewards, they all plug into the same weighted objective.
Which raises our next question: if the framework is so general, what was actually still missing? The answer is length flexibility.
From fixed to any-length generation
Most generative models assume a fixed-dimensional state space, such as a fixed sequence length or fixed pixel count, decided before generation starts. But most real design problems don’t come with the length pre-specified. The right length of a peptide binder, a small molecule drug candidate, or a reasoning trace is part of what you’re trying to discover. Forcing a fixed length places a constraint on the space of what we can discover.
Recent work on any-length discrete diffusion removes this constraint by letting the process insert tokens at arbitrary positions during generation, not just unmask pre-allocated ones. We build on the flexible-length MDM framework, which defines a joint stochastic interpolant over two kinds of actions:
Insertion: adding new mask tokens into a gap between existing tokens (growing the sequence).
Unmasking: revealing the identity of a mask token (the classic MDM step).
So the model now parameterizes two things rather than one:
Unmasking posterior: the categorical distribution over tokens, conditioned on the current state and context of the sequence.
Insertion expectation: the expected number of tokens to insert between every pair of tokens conditioned on the current context.
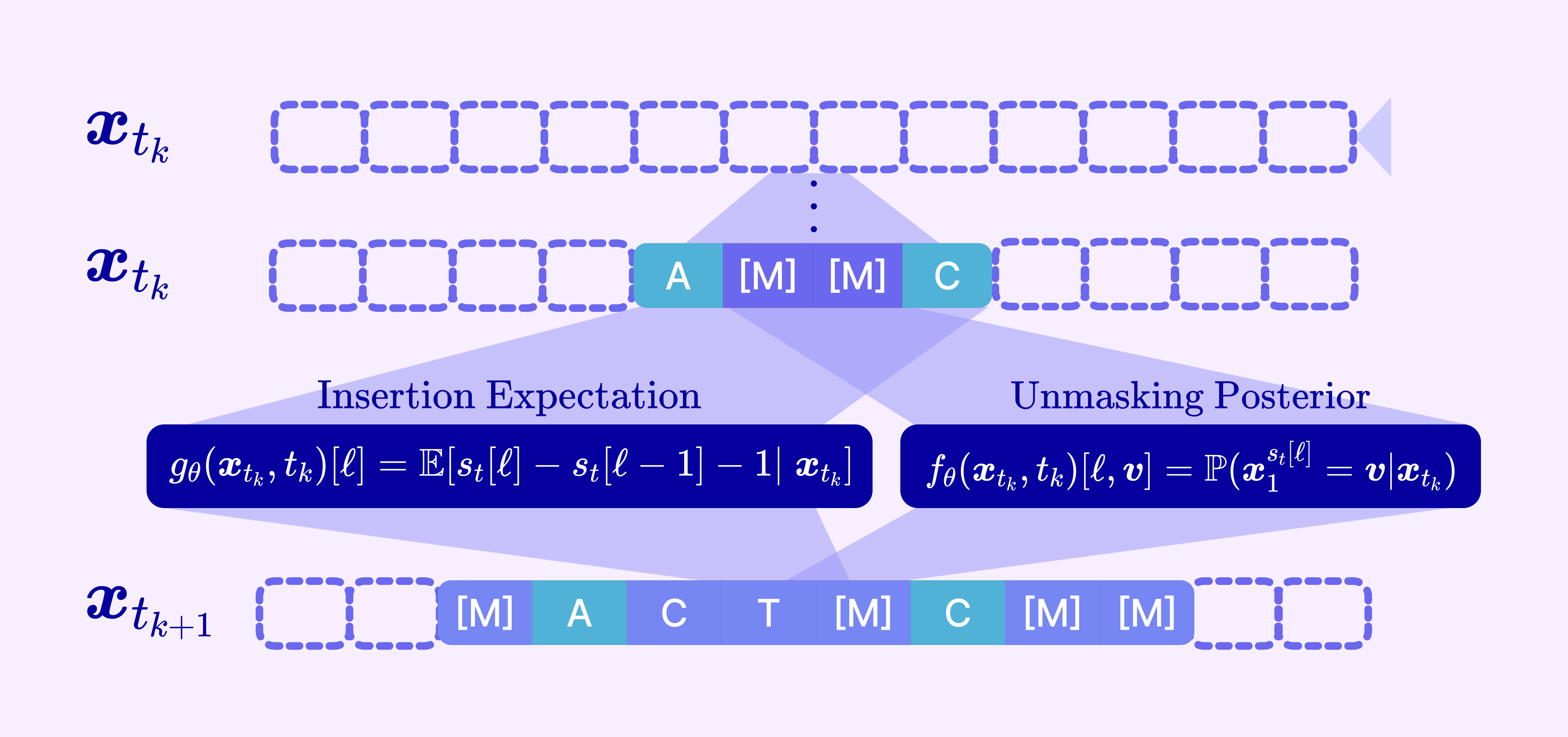
The corruption process runs both in reverse: it draws an insertion time and an unmasking time for each token, enforcing that a token can only be unmasked after it has been inserted, and trains a model on the partial sequence containing deleted and masked tokens.
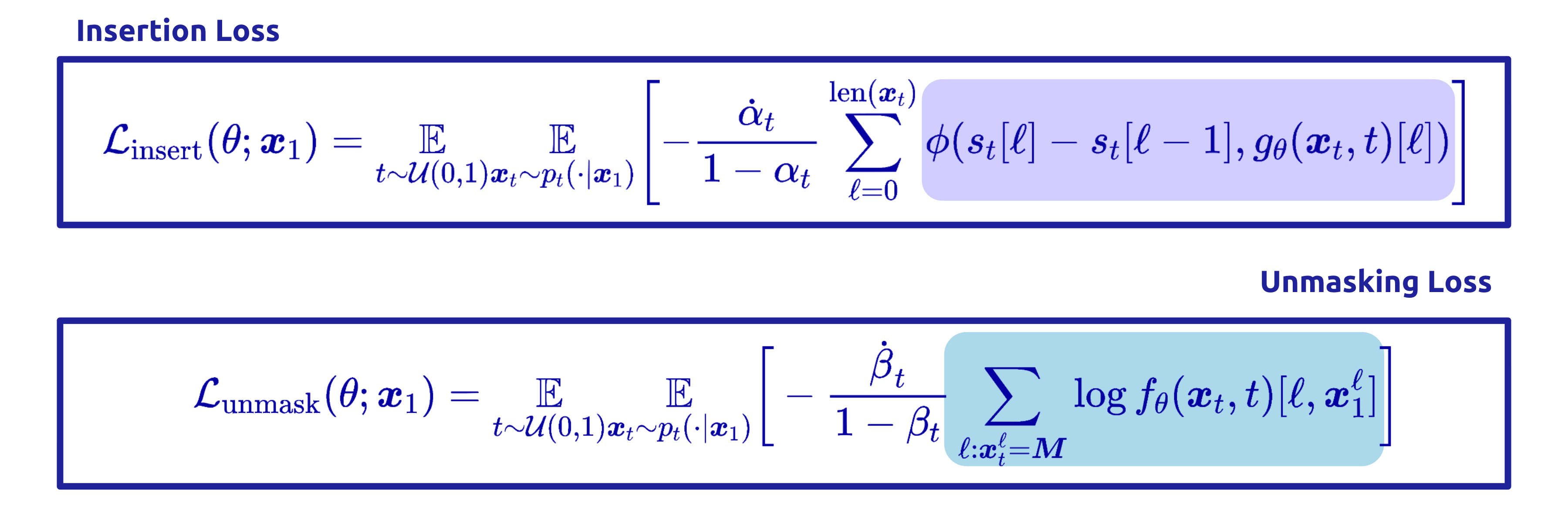
Training adds an insertion loss (matching the predicted insertion counts to the data, via a Bregman divergence) alongside the usual unmasking loss. The result is a single model that generates sequences of any length, deciding for itself how long the output should be. This is a strictly more expressive generative paradigm, which leads to its own challenges during reward alignment.
The challenge with aligning any-length generation
Reward-guided fine-tuning of fixed-length MDMs was already solved (with TR2-D2). But principled reward fine-tuning of any-length MDMs was essentially unexplored, and we found two primary challenges.
The larger action space results in more invalid sequences
In a fixed-length model, the only decisions are which token goes at each position. In an any-length model, every step also decides whether and where to insert and how many tokens, a vastly larger combinatorial action space that spans both unmasking and variable-length insertions.
This means that accuracy becomes highly sensitive to the trajectory the model takes, and the model becomes far more prone to generating invalid outputs. A SMILES string with a misplaced insertion doesn’t parse into a molecule at all. In our experiments, the pretrained any-length peptide model was valid only ~10% of the time, versus ~32% for its fixed-length counterpart. A larger action space means there are more ways to go wrong.
Optimizing joint stochastic processes and aligning the reward
You now have to optimize two coupled stochastic processes and align the reward simultaneously. Insertions and unmaskings aren’t independent. An insertion is only “good” if the tokens later unmasked into it are correct; an unmasking is only “good” if the surrounding insertions set up a valid context.
A bad insertion early on can ruin an otherwise perfect unmasking trajectory. So directly applying reward fine-tuning to an any-length model underperforms.
This leads to the question that motivated the paper:
Can we efficiently fine-tune any-length discrete diffusion models to sample from an intractable reward-tilted distribution while preserving high generation quality?
It’s not enough to optimize reward; we have to optimize reward while ensuring the sequences are valid and coherent, in a setting where the model has a much higher probability of error. And this is exactly the problem that A2D2 is designed to solve.
Introducing A2D2
A2D2 (Fine-Tuning Any-Length Discrete Diffusion for Adaptive Decoding) is a unified framework for reward-guided fine-tuning of any-length MDMs. It does three things at once: it fine-tunes the insertion policy and the unmasking policy to sample from the reward-tilted distribution, and it learns a quality-based inference schedule that decides, adaptively, when an insertion or unmasking is trustworthy enough to keep. Let’s walk through the three core ideas.
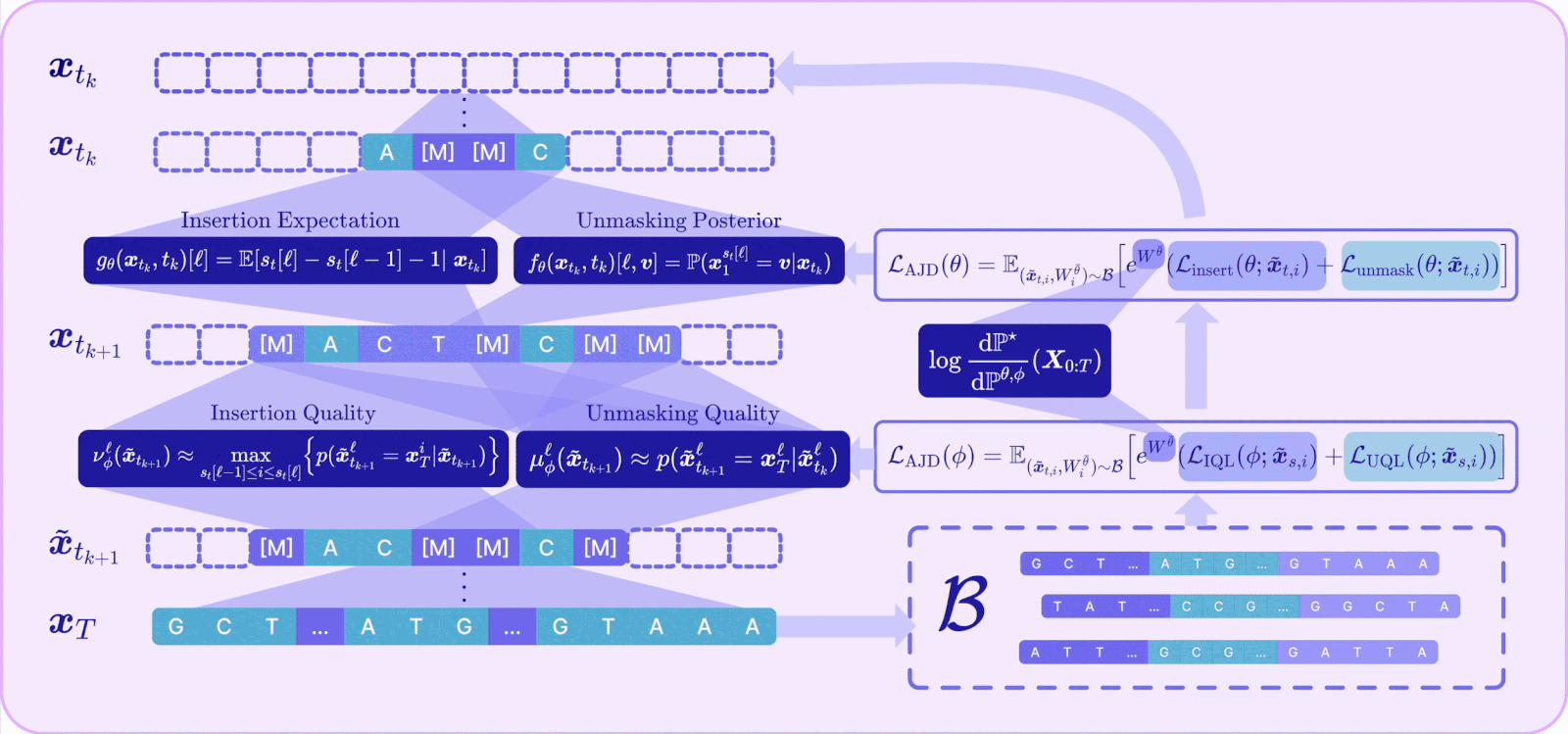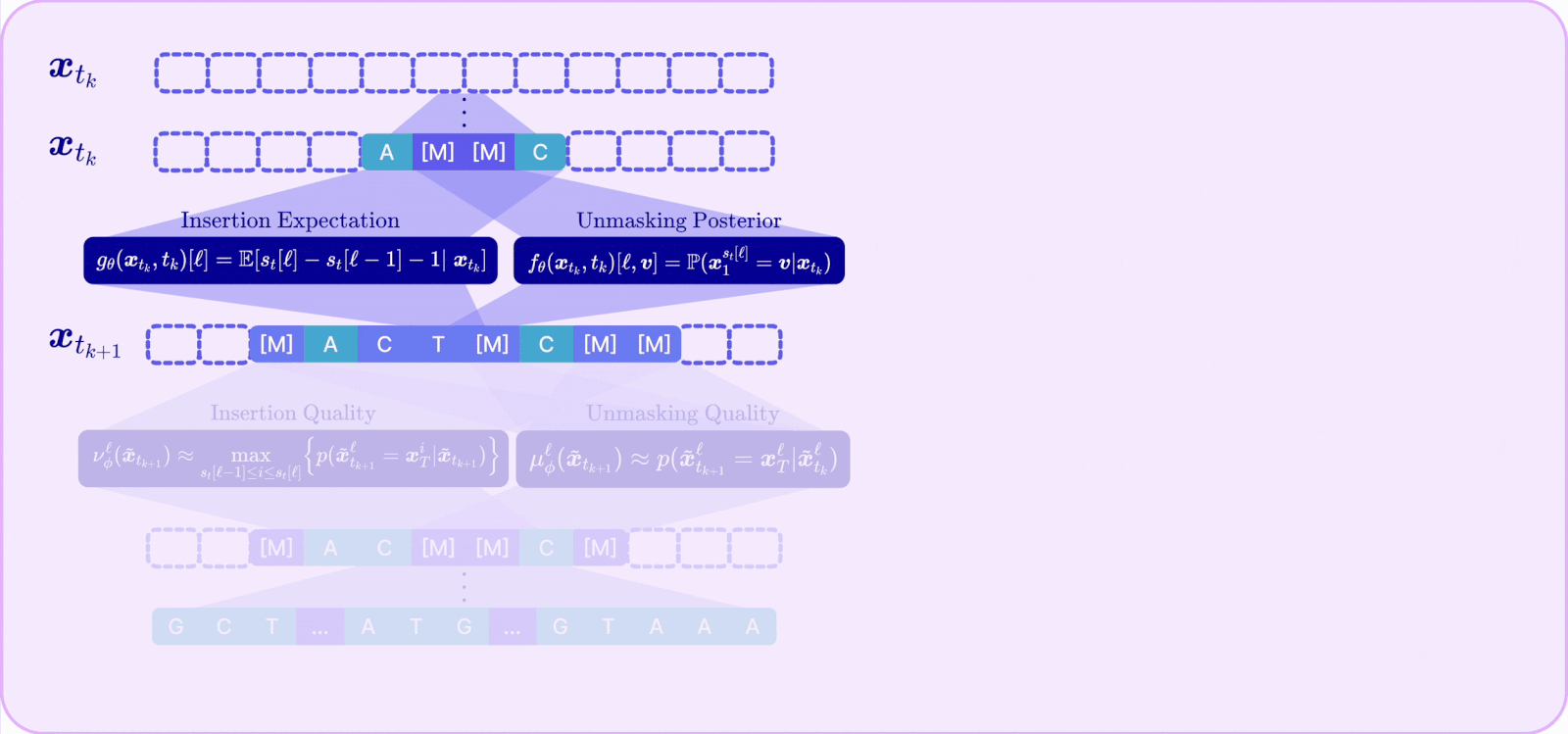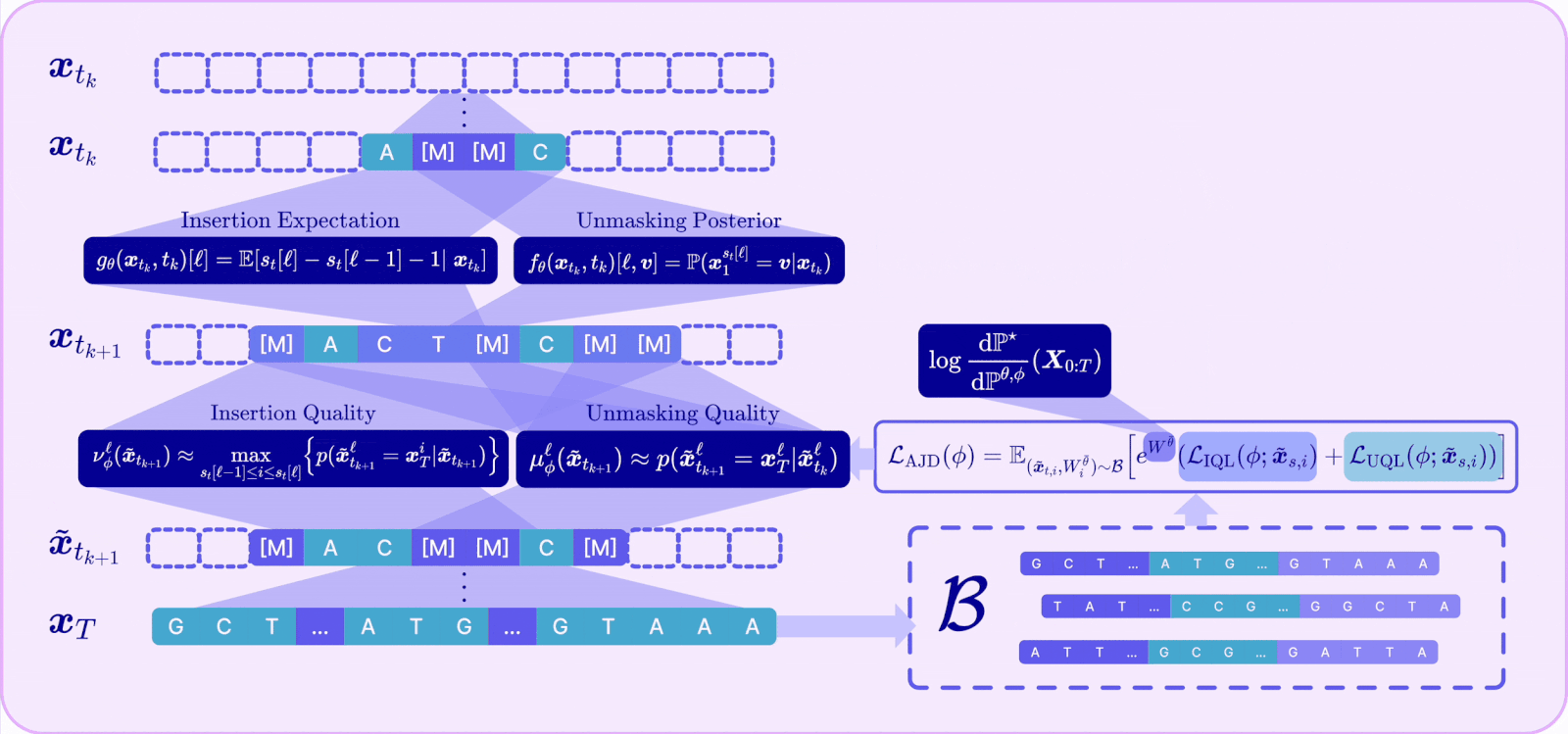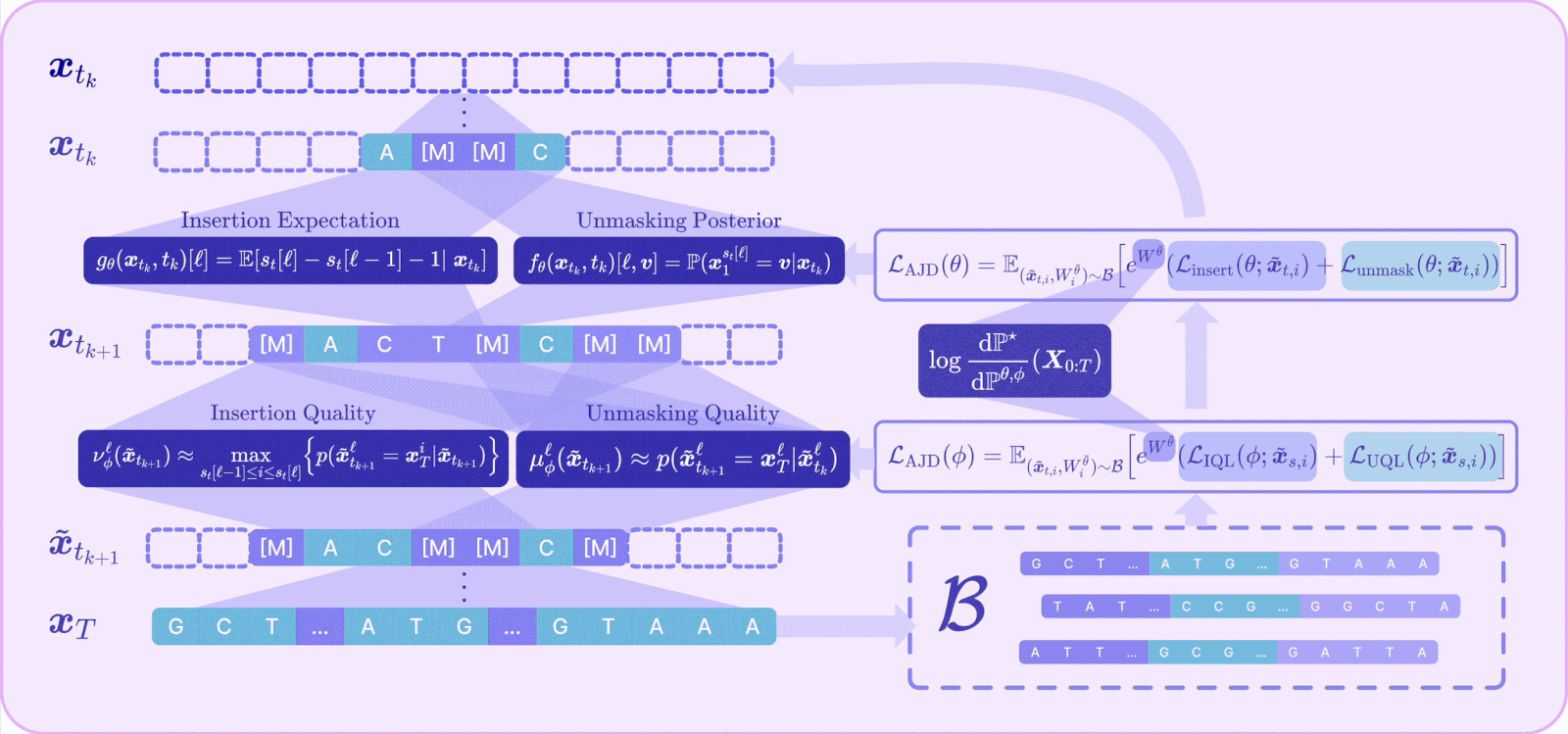
I. A Radon-Nikodym derivative for joint insertion-unmasking paths
To reward-align an any-length model, we first need the off-policy reweighting mechanism to work for the joint CTMC, which is the process that does both insertions and unmaskings. This required us to derive the Radon-Nikodym derivative for the joint insertion–unmasking path measure.
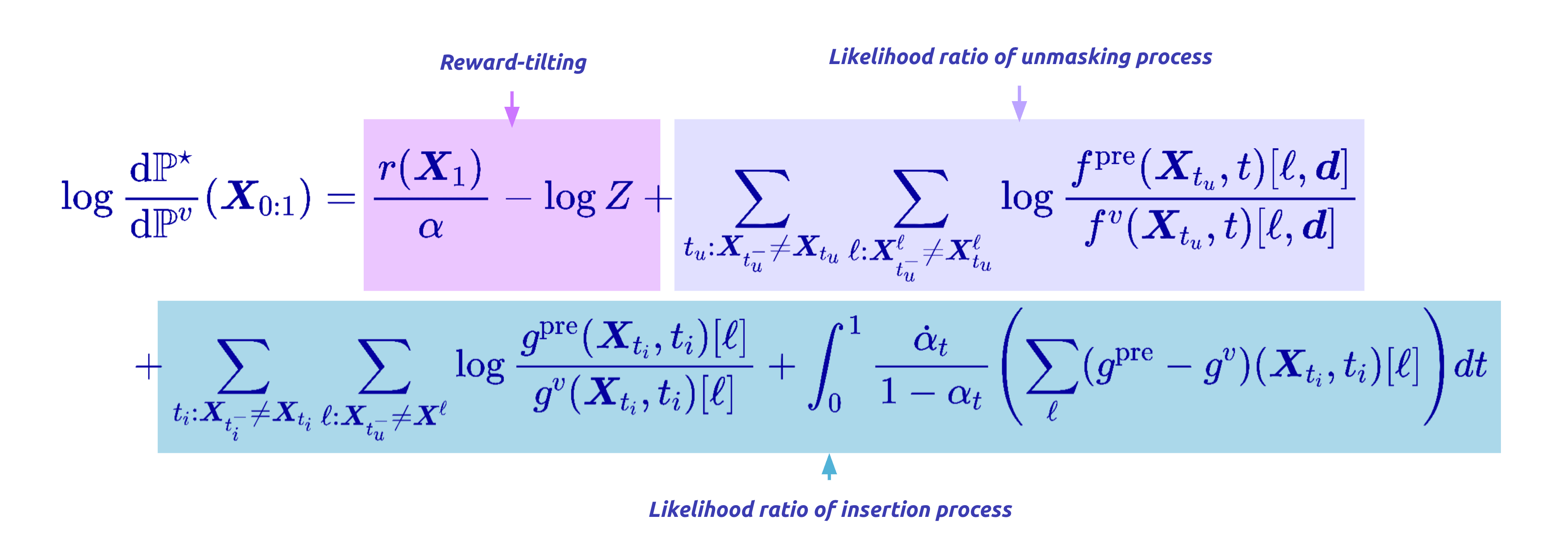
Intuitively, the importance weight now accumulates three kinds of contributions along a trajectory: the log-ratio of pretrained-to-finetuned rates at every unmasking jump, the same at every insertion jump, and an integral term accounting for the continuously varying insertion intensity, plus the terminal reward.
With that RND in hand, the off-policy idea we introduced earlier can be seamlessly adapted: we can sample trajectories from a fixed detached model, reweight them, and provably converge to the reward-tilted target, now over variable-length sequences.
II. Unmasking and insertion quality
The RND tells us how to align the reward, but it does not address the validity problem caused by the enlarged action space that makes the model prone to mistakes. To address this, A2D2 introduces a notion of quality for each kind of action and ties it directly to a concrete source of error.
The error is referred to as compounding parallelization error (CPE). Diffusion models unmask (and insert) many tokens in parallel per step for efficiency, but parallel decisions ignore the dependencies between the tokens being decided, and these small independence errors compound over the trajectory.
A2D2 defines two quantities to control CPE accumulation:
Unmasking quality (μ): the probability that a token being unmasked is actually the correct token given its context. High quality means this parallel unmasking action aligns with the context. We show that the probability of a successful parallel unmasking step is bounded by the product of the per-token unmasking qualities, so maximizing unmasking quality minimizes CPE.
Insertion quality (ν): the probability that a newly inserted mask will actually be decoded into a real token that belongs in that gap. We show that the probability of correctly reconstructing a sequence via insertions is upper-bounded by the product of insertion qualities, so maximizing insertion quality maximizes reconstruction likelihood.
Both are learned by lightweight prediction heads (trained with simple binary-cross-entropy losses whose unique minimizers are the true qualities).
At inference, these quality predictors let the model adaptively re-mask low-quality unmaskings and delete low-quality insertions, keeping only the high-quality, valid moves.
III. The Adaptive Joint Decoding (AJD) loss
The final component ties reward and quality into a single trainable objective. Plugging the joint RND into the off-policy cross-entropy and decomposing the path into its per-step insertion and unmasking terms yields the Adaptive Joint Decoding (AJD) loss:
This is just a reward-weighted sum of four familiar losses: train the unmasking policy, train the insertion policy, train the unmasking-quality head, and train the insertion-quality head — all on the same off-policy replay buffer, all tilted toward reward by the same importance weight.
We show that its unique minimizer is the optimal insertion and unmasking generator of the reward-tilted path measure, i.e., the model that simultaneously minimizes decoding error and samples from the reward-tilted distribution.
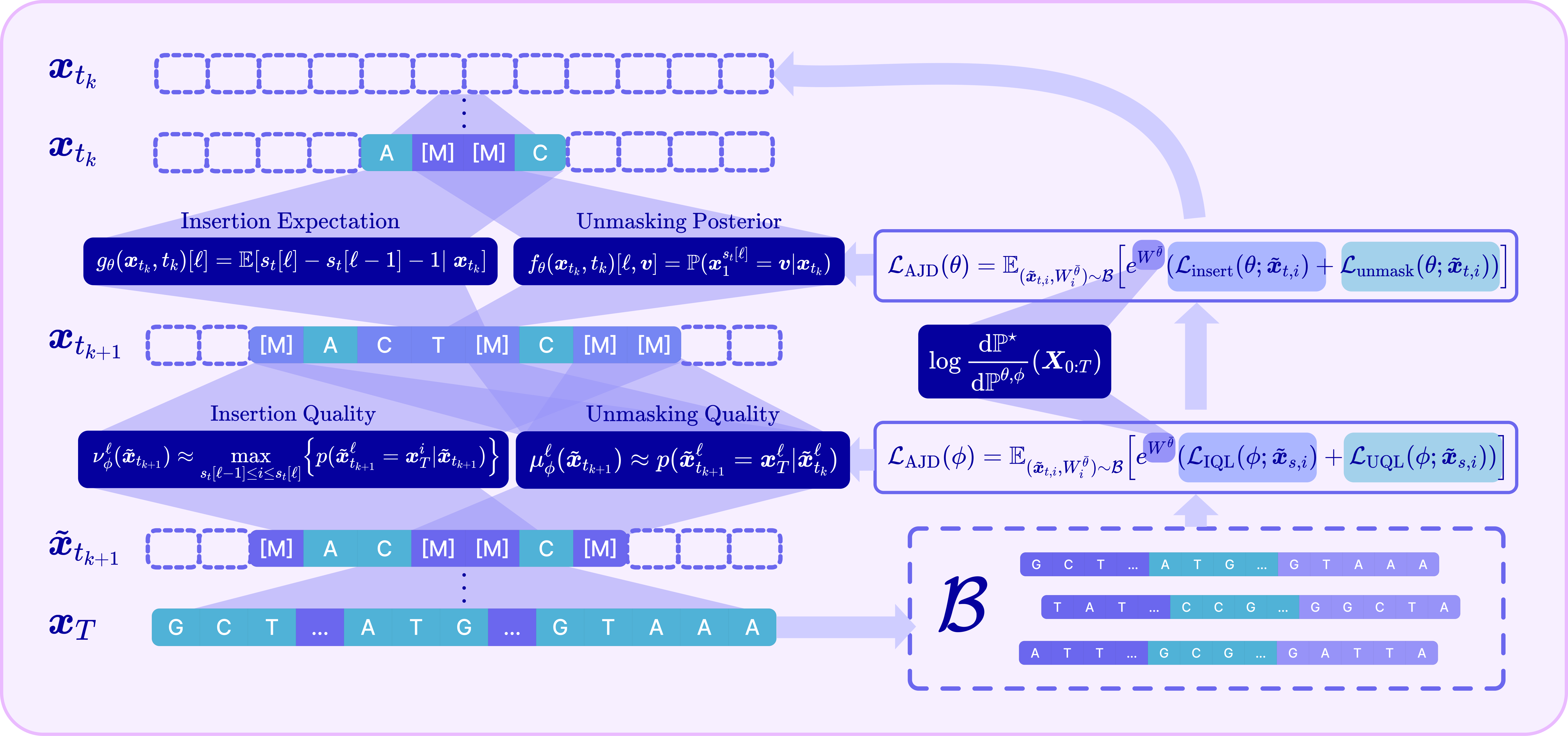
In practice, we optimize it with off-policy RL: sample a batch into a replay buffer (computing each trajectory’s importance weight), then update parameters on it. Because the policy heads are orders of magnitude larger than the quality heads, we alternate between updating one while freezing the other, which also removes the need to tune the relative weighting between the policy and quality losses.
Does it work?
Now for the experimental results! We applied A2D2 for drug-like small molecule design, peptide therapeutic design, and language reasoning on math word problems and code infilling.
On drug-like small molecules, fine-tuning the any-length model with A2D2 raised the fraction of valid, unique, drug-like, synthesizable molecules from 44% to 71%. This closes the gap to GenMol, the state-of-the-art fixed-length SAFE model, while operating in the strictly harder any-length regime. Ablating the quality predictors results in a drop in uniqueness, indicating that adaptive quality-based inference is what preserves diversity.
On multi-objective peptide design, A2D2 beat both fixed-length RL fine-tuning (TR2-D2) and the much more expensive inference-time guidance baseline on almost every property (e.g., raising TfR binding affinity from 7.76 to 10.19) without any inference-time search. And crucially, quality-based adaptive inference lifted sequence validity nearly fivefold, to ~49%, while optimizing rewards.
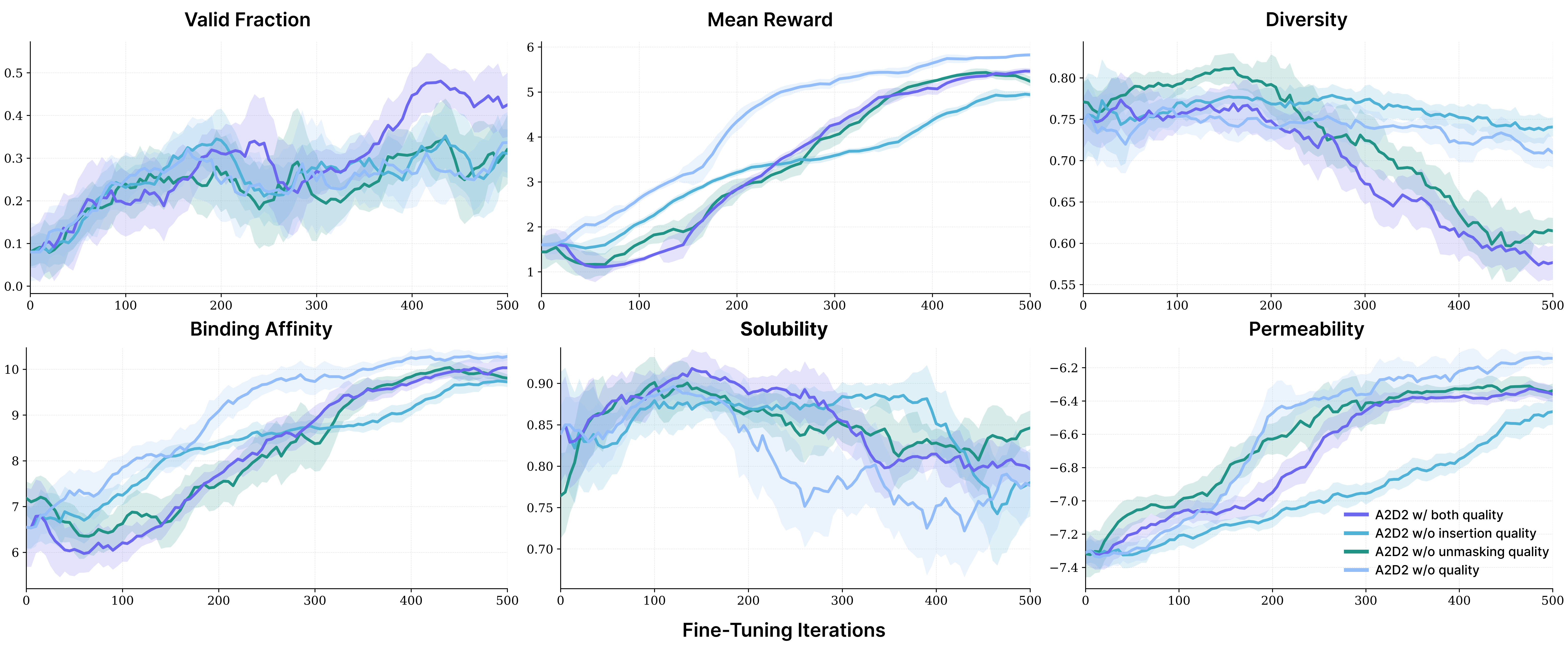
On language reasoning, adapting an 8B LLaDA-Base model to any-length and fine-tuning with A2D2 increased GSM8K Pass@1 from 35.7% → 61.0% at 128 sampling steps, beating the baseline’s best-ever score (41.4% at 1024 steps) using a fraction of the steps. On code infilling, A2D2 improved exact-match at every sampling budget.
Closing thoughts
A2D2 shows that we can align a generative model that decides its own length, and improve on both reward optimization and generation validity, which usually trade off against each other. While I’m ready to move on (for now) from reward alignment onto other problems, I still want to highlight a few directions I’m excited about in this space:
On the theory side, the idea of quality as a tool to control reconstruction error feels more general than any-length discrete diffusion. I think anywhere parallel generation trades speed for accuracy, and an adaptive quality schedule could recover the lost accuracy.
On the application side, the same framework should extend naturally to a broad range of sequence data, and I’d especially love to see any-length reward alignment applied to other biologically relevant tasks such as linker and conjugate design.
As always, huge shoutout to my amazing co-authors and advisors: Yuchen Zhu, Molei Tao, and Pranam Chatterjee. Make sure to read the full paper on arXiv or try out our code on GitHub.
Citation
If you find this article helpful for your publications, please consider citing our paper:
@article{tang2026a2d2,
title={A2D2: Fine-Tuning Any-Length Discrete Diffusion for Adaptive Decoding},
author={Sophia Tang and Yuchen Zhu and Molei Tao and Pranam Chatterjee},
journal={arXiv preprint arXiv:2606.13565},
year={2026}
}Alchemy Bio is a blog where I share transformative ideas in machine learning for biology. If you don’t want to miss upcoming posts, you should consider subscribing for free to have them delivered to your inbox.